
Es común oír que altas temperaturas, por sobre los 30 grados centígrados, sumado a una humedad relativa del aire bajo un 30% y un viento por sobre los 30 kilómetros por hora, disponen las condiciones ideales para los incendios forestales. La ventaja de esta fórmula es que es fácil de recordar y representa de manera sencilla un patrón que resume la información disponible. Sin embargo, la realidad puede ser un poco más compleja que esta simple fórmula.
Hicimos el ejercicio de descargar los datos de incendios publicados por la CONAF[1] para agregarle información meteorológica de la Dirección Meteorológica de Chile y evaluar el desempeño de diferentes herramientas predictivas. A la fecha de este ejercicio, sólo pudimos obtener datos de incendios cuya magnitud fuera mayor o igual a 200 hectáreas, e información meteorológica para esas zonas desde 2017 en adelante[2].
Un primer resultado del análisis es que las condiciones climáticas (temperatura, humedad y viento) para que ocurra un incendio de las características disponibles, no son iguales en todas las regiones. Esto se puede ver en la figura a continuación en que se muestra la relación entre las variables para cada región y la cantidad de incendios que ocurren con esas características.
Gráfico 1: Distribución de variables climáticas y ocurrencia de incendios por región.
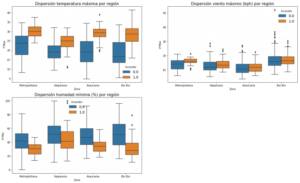
Fuente: Elaboración propia en base a datos de la CONAF y de la Dirección meteorológica de Chile.
De estos gráficos se infiere que la temperatura y la humedad son variables muy importantes. La mayoría de los puntos en que hay concentración de incendios ocurre desde los 25-30 grados en adelante y con niveles de humedad bajo el 40%, a excepción de Valparaíso en que se observan focos activos con mayores niveles de humedad. El viento parece ser importante en la región Metropolitana, pero es menos claro que sea un factor determinante en las otras regiones. Probablemente afecte a la duración y propagación de los focos de incendio, más que a la generación de los mismos.
En la segunda ronda de gráficos se puede observar el detalle de cada región y las relaciones específicas entre estas tres variables y la cantidad de incendios.
Gráfico 2: Dispersión de variables por región
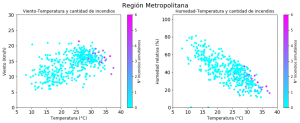
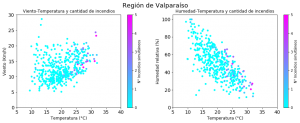

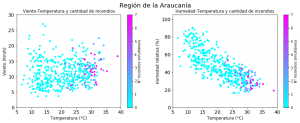
Fuente: Elaboración propia en base a datos de la CONAF y de la Dirección meteorológica de Chile.
El análisis anterior sugiere que podría haber potencial para desarrollar modelos predictivos (machine learning) que aprendan sobre los patrones y relaciones entre variables climáticas en cada región para anticipar la ocurrencia de incendios.
Sin embargo, antes de utilizar este tipo de herramientas, revisemos cómo le iría a un modelo simple tipo 30-30-30.
Tabla 1: Matriz de confusión modelo benchmark “30-30-30”.
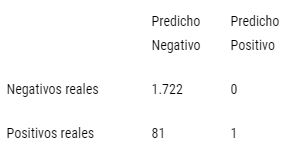
Fuente: Elaboración propia en base a datos de la CONAF y de la Dirección meteorológica de Chile.
Como vimos anteriormente en las visualizaciones, en estas regiones la velocidad máxima del viento casi nunca supera los 30 (km/h) por lo que esta regla es muy exigente y “nuestro modelo simple” sólo predice la ocurrencia de un incendio y en ese caso acierta.
Por lo anterior, relajaremos la restricción a algo más acorde a la realidad nacional con un segundo modelo, llamado 30-40-10 (T° mayor a 30°, humedad menor a 40% y velocidad del viento mayor a 10 km/h).
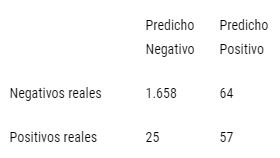
Tabla 2: Matriz de confusión modelo benchmark “30-40-10”.

Fuente: Elaboración propia en base a datos de la CONAF y de la Dirección meteorológica de Chile.
Con este ajuste, vemos que nuestro modelo fue capaz de anticipar 57 de los 82 incendios de gran magnitud (i.e. recall =69,5%). Sin embargo, hubo muchos casos en que el modelo anticipó incendio y en la realidad no hubo, acertando en 57 de 224 casos (i.e. precisión de 25,4%).
Dado lo anterior, quisimos explorar el potencial de modelos de machine learning para aprender de los patrones ocultos entre los distintos predictores.
Modelamos un problema de clasificación utilizando ensambles de árboles (Random forest y Gradient Boosting) entrenando con una fracción de los datos (80% y 5 grupos de validación cruzada) para predecir probabilidad de incendio. Los resultados muestran básicamente que si queremos detectar una cantidad similar de incendios (57 de 82) lo podemos hacer con mucho mayor precisión (47% vs 25%).
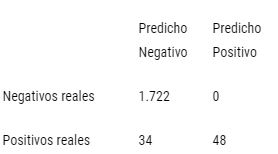
Tabla 3: Matriz de confusión modelo machine learning
Fuente: Elaboración propia en base a datos de la CONAF y de la Dirección meteorológica de Chile.
Además, un beneficio adicional del modelo es que si queremos que este prediga incendio sólo cuando está muy seguro (cuando estima una probabilidad muy alta), la precisión aumenta bruscamente. Por ejemplo, si es que predecimos incendio sólo cuando la probabilidad estimada es mayor al 60%, los resultados son los siguientes:
Tabla 4: Matriz de confusión modelo machine learning “exigente”.
Fuente: Elaboración propia en base a datos de la CONAF y de la Dirección meteorológica de Chile.
En este caso, obtuvimos un 100% de precisión a costa de unos pocos falsos negativos.
Este ejercicio permite concluir varias cosas. Lo primero, como es obvio, es que la información se puede usar para prevenir. Si el algoritmo predice una alta ocurrencia de incendio, se pueden tomar las medidas que estén al alcance para prevenir un incendio. Como se mostró, en muchos casos, un modelo un poco más sofisticado, tendrá muchos mejores resultados en prevención que lo que tendría un modelo simple tipo 30-30-30 o 30-40-10.
Lo segundo es que el análisis de datos puede ayudar a perseguir incendios intencionales. Si hay un incendio que no reunía las condiciones para que se propagara -según los algoritmos predictivos-, entonces es un sospechoso que debería ser revisado con detalle.
* Nota: toda la programación de los análisis de este artículo se pueden encontrar en github.com/jibatlle
[1] Para este ejercicio nos concentramos en cuatro de las regiones con mayor cantidad de incendios de gran magnitud (Metropolitana, Bio Bio, Valparaíso y Araucanía).
[2] Lamentablemente el 2017 fue un año extremadamente anormal en cuando a cantidad de incendios en relación con la historia (sobre todo en Valparaíso), por lo que en la medida que ampliemos los datos meteorológicos para incorporar más temporadas, será posible aprender y descubrir más patrones y con ello mejorar los análisis y la capacidad predictiva.
Por Jose Ignacio Batlle
Socio FK Datalab
30Fuente: Contrafactual.cl







